Методы аналитического модуля Infor CRM
От обычных CRM-систем, аналитические CRM (Infor CRM, SalesLogix) отличают способы достижения целей, поставленных перед специалистами, работающими в программе. С некоторых пор аналитические возможности CRM стали широко использоваться в специфических видах бизнеса – страховании, рекламе и банковском деле.
Введение
Обычно любое программное решение включает в себя аналитический и операционный модули. Операционный модуль CRM позволяет решать задачи удержания клиента при непосредственном контакте с ним, а аналитический служит инструментом прогнозирования поведения клиентов. В век передовых технологий это делается с помощью CRM системы.
Аналитический модуль современных CRM-систем (Infor CRM, SalesLogix) позволяет выполнять множество необходимых для успешного функционирования предприятия действий. При грамотном использовании подобного программного обеспечения можно не только провести качественный анализ предпочтений потребителя, но и выявить линию поведения клиентов в будущем. Это помогает определить эффективную стратегию, при следовании которой компания не просто получит максимальную прибыль, но и создаст положительный имидж в глазах потребителей.
Одной из главных задач аналитического модуля является выявление сегментов покупателей и оперативное изменение данных о них. Во многих сферах бизнеса в настоящее время требуется знание не только о том, когда клиент обратился в компанию и что приобрел, но и весь спектр информации о семейном положении покупателя, его социальном статусе, возрасте и прочих характеристиках. Эти характеристики важны и при непосредственном контакте с клиентом, но гораздо более значимыми они являются именно при анализе. Мало кто может знать, какая информация может пригодиться для предугадывания потребностей потребителя, поэтому важна каждая мелочь.
Столь мощный инструмент анализа, как специальный модуль CRM (Infor CRM, SalesLogix), во многом облегчает непростой труд рекламистов и маркетологов. Для последних особенно важно владеть информацией о сегментации рынка, чтобы вырабатывать максимально эффективную политику продвижения организации на рынке. Клиенты – это основная ценность организации, а их деятельность необходимо подвергать детальному анализу.
Методы аналитического модуля
Коллаборативная фильтрация
Коллаборативная фильтрация — это один из методов построения прогнозов в рекомендательных системах, использующий известные предпочтения группы пользователей для прогнозирования неизвестных предпочтений другого пользователя. Его основное допущение состоит в следующем: те, кто одинаково оценивали какие-либо предметы в прошлом, склонны давать похожие оценки другим предметам и в будущем. Например, с помощью коллаборативной фильтрации музыкальное приложение способно прогнозировать, какая музыка понравится пользователю, имея неполный список его предпочтений. Прогнозы составляются индивидуально для каждого пользователя, хотя используемая информация собрана от многих участников. Тем самым коллаборативная фильтрация отличается от более простого подхода, дающего усреднённую оценку для каждого объекта интереса, к примеру, базирующуюся на количестве поданных за него голосов.
Коллаборативная фильтрация разделяется на 3 основных подхода:
- Основанный на соседстве.
В данном подходе для активного пользователя подбирается подгруппа пользователей схожих с ним. Комбинация весов и оценок подгруппы используется для прогноза оценок активного пользователя.
- Основанный на модели.
Данный подход предоставляет рекомендации, измеряя параметры статистических моделей для оценок пользователей, построенных с помощью таких методов как, метод байесовских сетей, кластеризации, латентной семантической модели, такие как сингулярное разложение, вероятностный латентный семантический анализ, скрытое распределение Дирихле и марковской процесс принятия решений на основе моделей. Модели разрабатываются с использованием интеллектуального анализа данных, алгоритмов машинного обучения, чтобы найти закономерности на основе обучающих данных. Число параметров в модели может быть уменьшено в зависимости от типа с помощью метода главных компонент.
- Гибридный.
Данный подход объединяет в себе подход основанный на соседстве и основанный на модели. Гибридный подход является самым распространённым при разработке рекомендательных систем для коммерческих сайтов, так как он помогает преодолеть ограничения изначального оригинального подхода (основанного на соседстве) и улучшить качество предсказаний. Однако данный подход сложен и дорог в реализации и применении.
Ассоциативный анализ
Аффинитивный анализ (affinity analysis) — один из распространенных методов Data Mining. Цель данного метода — исследование взаимной связи между событиями, которые происходят совместно. Разновидностью аффинитивного анализа являетсяанализ рыночнойкорзины (market basket analysis), цель которого — обнаружить ассоциации между различными событиями, то есть найти правила для количественного описания взаимной связи между двумяили более событиями. Такие правила называютсяассоциативными правилами (associationrules).
Базовым понятием в теории ассоциативных правил является транзакция — некоторое множество событий, происходящих совместно. Типичная транзакция —приобретение клиентом товара в супермаркете. В подавляющем большинстве случаев клиент покупает не один товар, анабор товаров, который называется рыночной корзиной. При этом возникает вопрос: являетсяли покупка одного товара в корзине следствием или причиной покупки другого товара, то есть связаны ли данные события?
Эту связь и устанавливают ассоциативные правила. Следующее важное понятие — предметный набор.
Это непустое множество предметов,появившихся в одной транзакции.
Анализ рыночной корзины — это анализ наборов данных для определения комбинаций товаров, связанных между собой. Иными словами, производится поиск товаров, присутствие которых в транзакции влияет на вероятность наличия других товаров или комбинаций товаров.
Поддержка ассоциативного правила — это число транзакций , которые содержат как условие , так и следствие. Например, для ассоциации A > B можно записать:

Достоверность ассоциативного правила A > B представляет собой меру точности правила и определяется как отношение количества транзакций, содержащих и условие, и следствие , к количеству транзакций, содержащих только условие:

Если поддержка и достоверность достаточно высоки, можно с большой вероятностью утверждать, что любая будущая транзакция, которая включает условие, будет также содержать и следствие.
Аналитики могут отдавать предпочтение правилам, которые имеют только высокую поддержку или только высокую достоверность либо, что является наиболее частым, оба этих показателя. Правила, для которых значения поддержки или достоверности превышают определенный, заданный пользователем порог, называются сильными правилами (strong rules). Например, аналитика может интересовать , какие товары , покупаемые вместе в супермаркете, образуют ассоциации с минимальной поддержкой 20% и минимальной достоверностью 70%. А при анализе с целью обнаружения мошенничеств может потребоваться уменьшить поддержку до 1%, поскольку с мошенничеством связано сравнительно небольшое число транзакций.
Значимость ассоциативных правил
Методики поиска ассоциативных правил обнаруживают все ассоциации, которые удовлетворяют ограничениям на поддержку и достоверность, наложенным пользователем. Это приводит к необходимости рассматривать десятки и сотни тысяч ассоциаций, что делает невозможным обработку такого количества данных вручную. Число правил желательно уменьшить таким образом , чтобы проанализировать только наиболее значимые из них.
По этой причине при поиске ассоциативных правил используются дополнительные показатели, позволяющие оценить значимость правила. Можно выделить объективные и субъективные меры значимости правил. Объективными являются такие меры, как поддержка и достоверность, которые могут применяться независимо от конкретного приложения. Субъективные меры связаны со специальной информацией, определяемой пользователем в контексте решаемой задачи. Такими субъективными мерами являются лифт (lift) и левередж ( от англ . leverage — плечо , рычаг ). Лифт вычисляется следующим образом:
![]()
Лифт — это отношение частоты появления условия в транзакциях, которые также содержат и следствие, к частоте появления следствия в целом . Значения лифта большие, чем единица, показывают, что условие чаще появляется в транзакциях, содержащих следствие, чем в остальных . Можно сказать, что лифт является обобщенной мерой связи двух предметных наборов : при значениях лифта > 1 связь положительная, при 1 она отсутствует, а при значениях < 1 — отрицательная.
Другой мерой значимости правила, предложенной Г.Пятецким-Шапиро, является левередж:
![]()
Левередж — это разность между наблюдаемой частотой, с которой условие и следствие появляются совместно, и произведением частот появления (поддержек ) условия и следствия по отдельности.
Алгоритм Apriori
В основе алгоритма Apriori лежит понятие частого набора, который также можно назвать частым предметным набором, часто встречающимся множеством. Под частотой понимается простое количество транзакций, в которых содержится данный предметный набор. Тогда частыми наборами будут те из них, которые встречаются чаще, чем в заданном числе транзакций.
Методика поиска ассоциативных правил с использованием частых наборов состоит из двух шагов:
- Следует найти частые наборы.
- На их основе необходимо сгенерировать ассоциативные правила, удовлетворяющие условиям минимальной поддержки и достоверности.
Чтобы сократить пространство поиска ассоциативных правил, алгоритм Apriori использует свойство антимонотонности. Данное полезное свойство позволяет значительно уменьшить пространство поиска ассоциативных правил.
После того как все частые предметные наборы найдены, можно переходить к генерации на их основе ассоциативных правил . Для этого к каждому частому предметному набору s, полученному на основе множества транзакций D, нужно применить процедуру, состоящую из двух шагов:
- Генерируются все возможные поднаборы s.
- Если поднабор ss является непустым поднабором s, то рассматривается ассоциативное правило R : ss > (s – ss), где s – ss представляет собой набор s без поднабора ss . R будет считаться ассоциативным правилом, если будет удовлетворять условию заданного минимума поддержки и достоверности . Данная процедура повторяется для каждого подмножества ss из s .
Кластерный анализ. EM-алгоритм
EM-алгоритм — алгоритм, используемый для нахождения оценок максимального правдоподобия параметров вероятностных моделей, в случае, когда модель зависит от некоторых скрытых переменных.
Идея алгоритма заключается в следующем. Искусственно вводится вспомогательный вектор скрытых переменных , обладающий двумя свойствами.
- С одной стороны, он может быть вычислен, если известны значения вектора параметров Q .
- С другой стороны, поиск максимума правдоподобия сильно упрощается, если известны значения скрытых переменных.
EM-алгоритм состоит из итерационного повторения двух шагов.
- На E-шаге вычисляется ожидаемое значение (expectation) вектора скрытых переменных по текущему приближению вектора параметров Q.
- На М-шаге решается задача максимизации правдоподобия (maximization) и находится следующее приближение вектора по текущим значениям векторов G и Q .
Заключение
Данные методы прекрасно взаимодополняют друг друга:
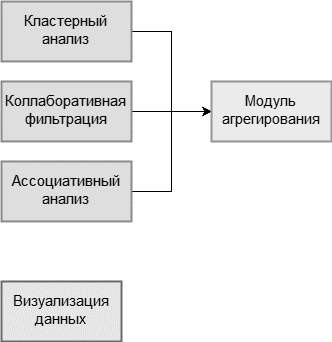
Коллаборативная фильтрация анализирует таблицу покупок клиентов и находит наиболее близких. В модуле агрегирования берутся все товары схожих клиентов которых нет у выбранного.
Ассоциативный анализ находит ассоциации между товарами и позволяет добавлять следствия ассоциаций в список рекомендованных товаров при наличии причины в товарах клиента.
Кластерный анализ помогает решить проблему «холодного старта», то есть, если у выбранного клиента нет купленных товаров, то первые два вида анализа не могут рекомендовать товары, но анализируя метаданные клиентов, можно разделить их на кластеры и уже классифицируя клиента по его метаданным, можно рекомендовать наиболее популярные товары среди клиентов его класса.
Свяжитесь с нами
Более подробную информацию Вы можете получить, позвонив в "ФБ Консалт" по тел.: +7 (495) 781–6400 или отправив запрос по электронной почте: info@fbconsult.ru. Специалисты компании с радостью ответят на все интересующие Вас вопросы.Обращайтесь!